0%
pytest 使用
pytest 上手比较简单.
环境
Python
最好在工作目录建个虚拟环境:1
2python -m venv venv
source venv/bin/activate
pytest
安装1
pip install pytest
资源
文档
在线文档
PDF
想要运行示例,看在线文档第一页就行.
想要系统学习,个人感觉看PDF文档比较好.
帮助
1 | pytest --help |
可以看到所有的命令行参数及输入输出控制.
其中有一个比较重要的参数可以详细看看:
1 | general: |
pytest 默认会collect test_.py 或者 _test.py module 中 以test为前缀的function 或者以Test为前缀的class中以test为前缀的function(no init),
通过这个参数可以自定义控制
示例
入门例子
在工作目录新建:test_sample.py1
2
3
4
5
6# test_sample.py
def inc(x):
return x + 1
def test_answer():
assert inc(3) == 5
当前目录运行:1
pytest
便可以看到report.
Report 示例
1 | (venv) ➜ ln_pytest pytest |
Feature
用例(进入) 默认情况下自动发现关键词:“test”,
断言(判断) 灵活易懂
报告
依赖
1 | pip install allure-pytest |
生成测试结果数据
1 | pytest --alluredir ./result/ |
将结果渲染到页面
1 | allure serve result -h 127.0.0.1 -p 8080 |
知识图谱构建思路
知识图谱:语义知识形式化表达的框架,节点表示本体,边表示关系.
知识图谱建设对众多NLP基础技术依赖很大,是一个系统工程,需要整体考虑.
所以梳理一下思路对整体认识有帮助.
但,这是一个更偏工程技术的挑战,而且成本也不小,所以既考规划也考技术,整理思路可能只对思路有帮助,实际建设过程却非常有可能遇到七七八八的问题.
需求
这个是第一位需要考虑的,这个会对大范围进行限定,因为会从“我要建知识图谱” => “我要建xxxx的知识图谱”.
需求会明确所面临的是开放领域还是专业领域,这个区别会造成数据来源的不同,以及对结果的要求高低也会不一样.
开放领域的数据可能一般通过从互联网爬取获得.
专业领域一般都有自己的数据积累,更新途径.
专业领域的知识图谱可能原本就会有一些相关应用,只是不叫知识图谱罢了,所以其要求也会更高.
技术
实体提取、关系提取、图谱存储、检索等
实体提取
- 词典匹配 | 有了词典后就很简单快速,关键是如果要更新的就需要维护词典
- 统计方法(NER) | 将NER问题转换为序列标注问题,一共那么几个标记,根据训练数据分布,计算当前语序下每个标记的概率,选概率最大的作为标记,这可以识别未登录词
关系提取
如果全部的关系集合预先指定好的话(比如谓词集合),任务也可视为当两个实体同时出现时实体间关系的分类问题.如果不当成分类问题可能就需要当成一个生成问题,根据句法分析后的依存关系生成实体间的关系.
基于依存关系生成主要基于句法分析和依存模版进行关系提取,可以看看EntityRelation的Python工具包实现,及对应的论文Chinese Open Relation Extraction and Knowledge Base
Establishment
关系分类大体可以分为无监督方法(基于模版),监督方法(基于特征/基于核函数/基于深度学习)
基于模版根据固定的语法格式提取实体间的关系,模版的生成可以是专家根据语言规则生成也可以用统计方法生成(利用搜索引擎等其它外部工具验证模版).
人工模版判断实体的上下位关系的准确率比较高,是因为这个模版所涉及到的表达形式比较固定,但对于其它关系可能就比较困难.
其他关系可以考虑使用统计生成模版,步骤是选择一个关系涉及到的实体对提交到搜索引擎,保留结果中包含实体对的的最长子串,这样会可能会得到多个模版,计算每个模版的置信度(只提交问题实体到搜索引擎,取包含实体的结果作为分母,契合某个模版的结果作为其模版的分子计算置信度),可以根据置信度阀值或者TopN提取模版.
基于特征就是根据标记数据训练分类模型,分类模型有很多可选,特征一般可以考虑(词汇相关/数值相关/类型相关/依存相关等等)
基于核函数利用空间转换计算相似度进行关系分类,方法复杂度比较高
基于深度学习从训练数据利用端到端对关系进行打分排序,进行关系分类
图谱存储
关系型数据库/图数据库
前者更新快,查询慢
后者查询快,更新慢
但是前者的使用成本可能会小一些,后者由于是一个相对新,可能需要趟更多的坑.包括但不限于图查询,图索引,子图优化等
检索
SQL/SPARQL
应用
包括知识推理在内应该属于应用范围,
其它应用领域可能有:搜索引擎,智能问答,推荐系统等
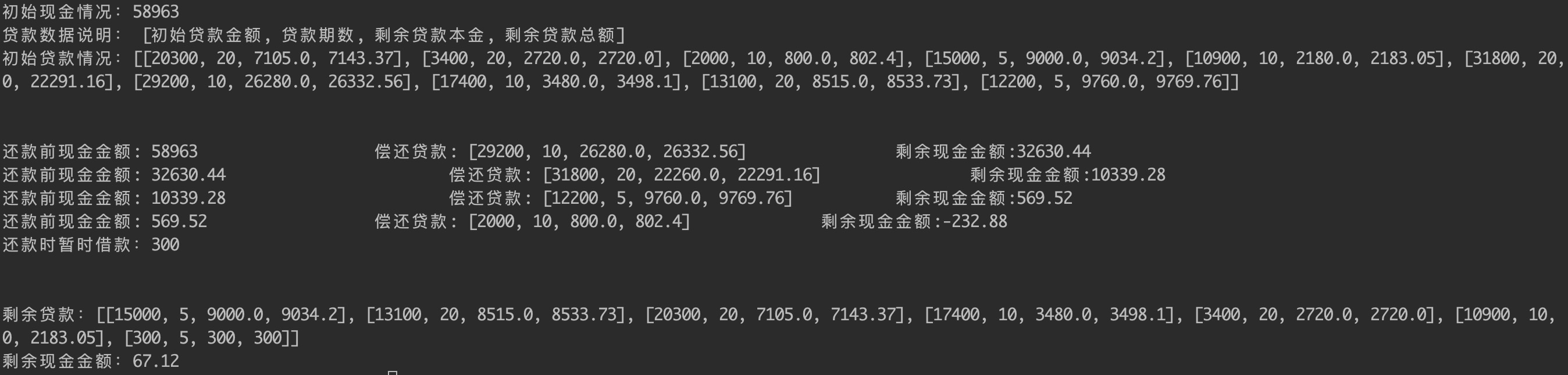
微粒贷还款问题
起源
yuange1975 在微博发布了一个趣味问题,看到觉得挺有意思,试着做了一下,相比原需求,多写了一个贷款数据生成的类,便于测试.
需求介绍及算法思路都在代码中注释,最终正确结果等yuange公布.
1 | """ |
示例结果